Tersedia paket workstation, DGX Spark, RTX 5090 office server, dan enterprise server.
Local AI Server untuk Perusahaan
Jawaban singkat: hal utama tentang Local AI Server untuk Perusahaan adalah ini: Rama Digital membantu perusahaan menyiapkan hardware, local AI model, OpenClaw, knowledge base, akses tim, training, dan handover agar AI bisa berjalan di lingkungan...
Rama Digital membantu perusahaan menyiapkan hardware, local AI model, OpenClaw, knowledge base, akses tim, training, dan handover agar AI bisa berjalan di lingkungan internal perusahaan.
2-6 mingguTimeline
Data lebih terkontrol, AI siap dipakai timOutcome
Tergantung ketersediaan hardware, scope knowledge base, jumlah user, dan kebutuhan network internal.
Ukuran model disesuaikan paket. Speed tertinggi biasanya untuk model kecil-menengah, model besar fokus quality mode.
Checkout membuat invoice. Tidak memakai payment gateway untuk paket hardware dan setup ini.
Job to be done
"Saya ingin perusahaan punya AI lokal yang bisa membaca dokumen internal, membantu tim, dan tetap punya kontrol lebih besar atas data serta akses user."
Cocok untuk Anda jika...
- Ingin hasil terukur, bukan sekadar aktivitas
- Butuh eksekusi cepat tanpa drama operasional
- Mau sistem yang bisa tim kelola setelah handover
Yang Anda dapatkan
- 1
Assessment kebutuhan, user, data, dan workload AI internal
- 2
Pengadaan atau validasi hardware AI sesuai paket
- 3
Instalasi OS, driver GPU, runtime local model, dan baseline security
- 4
Setup model lokal, OpenClaw, akses browser/API/LAN, dan knowledge base awal
- 5
Benchmark performa, dokumentasi, training tim, dan support masa setup
Paket layanan
Pilih format yang paling sesuai dengan tahap bisnis Anda
Struktur paket mengikuti penawaran lama, sementara desain dan komponen mengikuti sistem UI terbaru.
Paket 11-3 user ringan
Local AI Workstation
Untuk owner, founder, developer, atau divisi kecil yang ingin mulai memakai AI lokal untuk drafting, coding, analisa dokumen, dan knowledge assistant sederhana.
Rp 99.000.000Estimasi 2-3 minggu
- Hardware AI workstation kelas RTX 4070 Ti Super / RTX 4080 Super atau setara
- RAM 64GB dan NVMe 2TB
- Model 4B-12B quantized, dengan target >100 tokens/second untuk model kecil seperti Gemma 4B/E4B pada konfigurasi yang sesuai
- Instalasi OS, driver GPU, local AI runtime, dan model awal
- Setup OpenClaw basic, benchmark awal, dokumentasi, dan training online 1 sesi
Paket 2Compact AI appliance
DGX Spark Edition
Untuk perusahaan, founder, lab internal, atau tim teknologi yang ingin perangkat AI compact berbasis NVIDIA Grace Blackwell dengan memory besar dan stack NVIDIA resmi.
Rp 229.000.000Estimasi 2-4 minggu
- NVIDIA DGX Spark Founders Edition 4TB atau unit setara sesuai ketersediaan
- 128GB unified memory dan 4TB NVMe storage
- Cocok untuk local AI agent, knowledge assistant, prototyping, dan inference model besar berbasis quantization
- Setup local AI runtime, model kecil-menengah untuk daily use, dan model besar untuk quality/prototyping mode
- Setup OpenClaw basic, akses internal, benchmark awal, dokumentasi, training 1 hari, dan support setup 14 hari
Paket 33-8 user internal
Local AI Office Server RTX 5090
Untuk perusahaan yang ingin AI lokal dipakai beberapa orang internal dengan performa lebih lega untuk marketing, sales, support, operasional, atau management.
Rp 249.000.000Estimasi 3-5 minggu
- Hardware AI server/workstation kelas RTX 5090 32GB atau setara
- RAM 128GB dan NVMe 4TB total storage
- Model 4B-32B quantized: 4B/E4B cepat, 12B nyaman, 27B/32B untuk quality mode
- Setup model cepat + model quality mode, OpenClaw untuk beberapa workflow awal, dan akses browser/API/LAN
- Basic knowledge base, benchmark performa, dokumentasi, training tim 1 hari, dan support setup 14 hari
Paket 4Multi-user & governance
Enterprise AI Agent Server
Untuk perusahaan yang ingin membangun infrastruktur AI lokal sebagai bagian dari operasional jangka panjang, dengan user lintas departemen, governance, dan workflow approval.
Mulai Rp 499.000.000Estimasi 4-8 minggu
- Hardware workstation/server class dengan GPU profesional 48GB VRAM atau lebih sesuai quotation
- RAM 128GB-256GB, NVMe 4TB-8TB, dan network setup untuk akses internal
- Model 32B-70B quantized, tergantung konfigurasi final dan kebutuhan context
- OpenClaw untuk AI agent management, role, permission, approval flow, dan log dasar
- Knowledge base awal, SOP penggunaan, training tim, benchmark, handover teknis, dan support setup 30 hari
Deliverables
Output yang jelas, dampak yang terukur
Setiap area pengerjaan punya output konkret dan dampak nyata untuk bisnis Anda.
AreaOutputDampak Bisnis
Specification & SizingJumlah user, jenis dokumen, ukuran model, storage, akses, dan risiko data dipetakan sebelum hardware dipakai Perusahaan membeli konfigurasi yang sesuai kebutuhan, bukan sekadar mesin mahal
Hardware & RuntimeGPU workstation, DGX Spark, atau server class disiapkan dengan OS, driver, runtime, model, dan benchmark awal AI lokal bisa langsung diuji untuk pekerjaan nyata
Agent & Knowledge BaseOpenClaw, akses internal, workflow awal, dan knowledge base basic dipasang sesuai scope paket Tim mulai memakai AI untuk SOP, dokumen, drafting, dan bantuan operasional
Training & HandoverTraining, SOP penggunaan, batasan data, dokumentasi, dan support setup diberikan ke tim Adopsi tidak berhenti di teknisi, tapi bisa dipakai oleh user bisnis
Masalah bisnis
Ketika AI mulai membaca data internal, pendekatannya harus lebih serius
Cloud AI tetap berguna untuk pekerjaan umum. Tetapi saat AI mulai membaca SOP, dokumen customer, pipeline sales, laporan operasional, atau knowledge perusahaan, perusahaan butuh kontrol akses, lokasi data, dan proses review yang lebih jelas.
Data tidak semuanya cocok keluar ke cloud
Dokumen internal, data customer, kontrak, laporan finance, dan SOP sensitif perlu jalur penggunaan AI yang lebih terkendali.
Tim butuh AI yang konsisten dengan knowledge perusahaan
Server lokal bisa dipakai sebagai basis knowledge assistant, RAG, dan agent internal yang membaca dokumen versi perusahaan.
AI agent perlu governance
Workflow agent perlu role, permission, approval, logging, dan batasan aksi agar aman dipakai lintas divisi.
Spesifikasi teknis
Spesifikasi dipilih berdasarkan ukuran model, jumlah user, dan target kerja
Workstation 16GB VRAM
Model 4B-12B quantized- RTX 4070 Ti Super / RTX 4080 Super class
- RAM 64GB
- NVMe 2TB
- 1-3 user ringan
- Target >100 TPS untuk Gemma 4B/E4B pada konfigurasi sesuai
DGX Spark 128GB unified memory
Compact AI appliance- NVIDIA Grace Blackwell GB10 class
- 128GB unified memory
- 4TB NVMe
- Prototyping dan local agent
- Kuat di memory capacity, bukan raw TPS tertinggi
RTX 5090 Office Server
Model 4B-32B quantized- RTX 5090 32GB atau setara
- RAM 128GB
- NVMe 4TB
- 3-8 user internal
- Model kecil cepat + model quality mode
Enterprise GPU 48GB+
Model 32B-70B quantized- GPU profesional 48GB VRAM atau lebih
- RAM 128GB-256GB
- NVMe 4TB-8TB
- Role dan approval flow
- Cocok untuk multi-user dan governance
Estimasi timeline
Timeline pengerjaan dibuat bertahap agar hardware, software, dan tim siap bersamaan
Minggu 1 - Assessment dan finalisasi konfigurasi
Rama Digital memetakan jumlah user, jenis dokumen, kebutuhan model, lokasi server, network, keamanan, dan memilih konfigurasi hardware final.
Minggu 2 - Pengadaan, instalasi, dan baseline server
Hardware disiapkan, OS dan driver GPU dipasang, runtime local AI dikonfigurasi, lalu dilakukan hardening awal dan test stabilitas.
Minggu 3 - Model, OpenClaw, akses internal, dan benchmark
Model kecil dan quality mode dipasang, OpenClaw dikonfigurasi, akses browser/API/LAN disiapkan, lalu performa awal diuji dengan workload yang disepakati.
Minggu 4-6 - Knowledge base, training, UAT, dan handover
Untuk paket Office dan Enterprise, knowledge base awal, role, approval, dokumentasi, training, dan user acceptance test dijalankan sebelum handover final.
Benefit operasional
Manfaat utamanya bukan hanya punya mesin AI, tapi punya sistem yang bisa dipakai perusahaan
Data dan dokumen internal lebih terkendali karena pemrosesan utama bisa berjalan di lingkungan perusahaan
Tim bisa memakai AI assistant untuk SOP, dokumen, laporan, drafting, riset internal, dan support knowledge
Perusahaan punya opsi model kecil cepat untuk daily work dan model lebih besar untuk quality mode
OpenClaw membantu mengelola agent, workflow, approval, dan catatan aktivitas supaya tidak liar
Training dan SOP membantu user bisnis memahami batasan data, review manusia, dan cara memakai AI dengan aman
Checkout manual transfer membuat proses pembelian hardware dan jasa lebih rapi untuk kebutuhan invoice perusahaan
Catatan performa
Klaim performa selalu dikaitkan dengan model, quantization, context, dan runtime
Untuk model kecil-menengah seperti Gemma 4B/E4B, konfigurasi tertentu dapat ditargetkan di atas 100 tokens/second. Untuk model 12B, 27B, 32B, atau 70B, fokus biasanya bergeser ke kualitas output, kapasitas context, stabilitas, dan jumlah user.
Speed mode
Dipakai untuk pekerjaan harian yang butuh respons cepat seperti drafting, summarization ringan, coding helper, dan task operasional pendek.
Quality mode
Dipakai untuk analisa lebih berat, dokumen lebih panjang, reasoning lebih dalam, atau kebutuhan output yang butuh model lebih besar.
Benchmark sebelum handover
Setiap paket diuji dengan model dan prompt yang disepakati agar perusahaan tahu batas realistis mesin yang dibeli.

OpenClaw & AI Operasional
Lima Lapisan Engineering AI Agent: Prompt, Context, Harness, Loop, dan Graph
Peta operasional untuk memisahkan prompt, context, harness, loop, dan graph agar kegagalan AI agent dapat dilokalisasi, diuji, dan diperbaiki pada lapisan yang tepat.
OpenClaw & AI Operasional
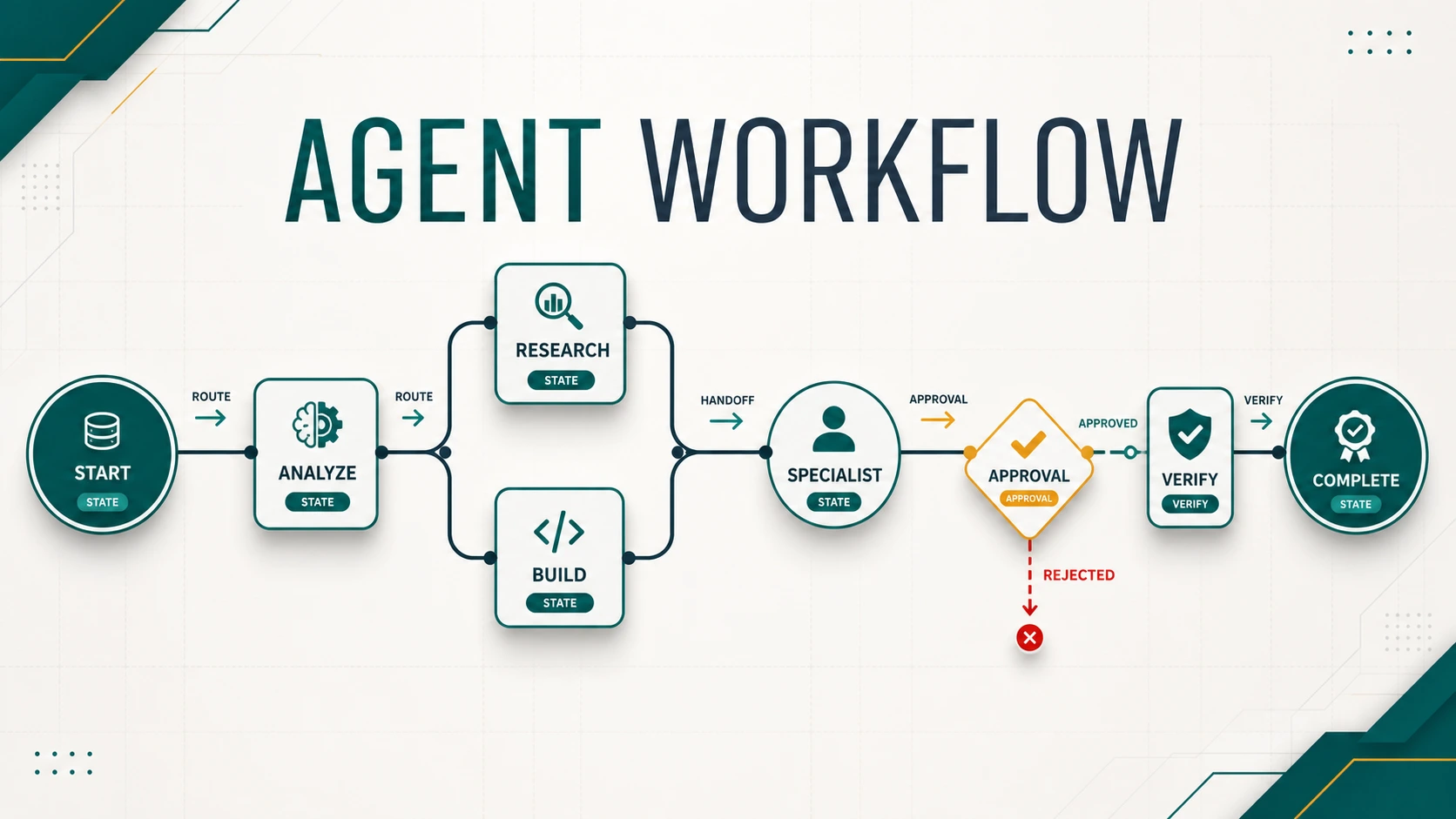
Graph-Based Agent Workflow: Nodes, State, Routing, Handoff, dan Approval
Graph-based workflow membuat state, route, handoff, approval, loop, parallel branch, dan recovery AI agent terlihat serta dapat diuji secara operasional.

OpenClaw & AI Operasional
Prompt Engineering 2026: Dari Instruksi ke Tool Schema, Eval, dan Acceptance Criteria
Prompt engineering tetap penting, tetapi unit kerjanya kini mencakup kontrak instruksi, tool schema, structured output, acceptance criteria, versioning, dan eval.
OpenClaw & AI Operasional
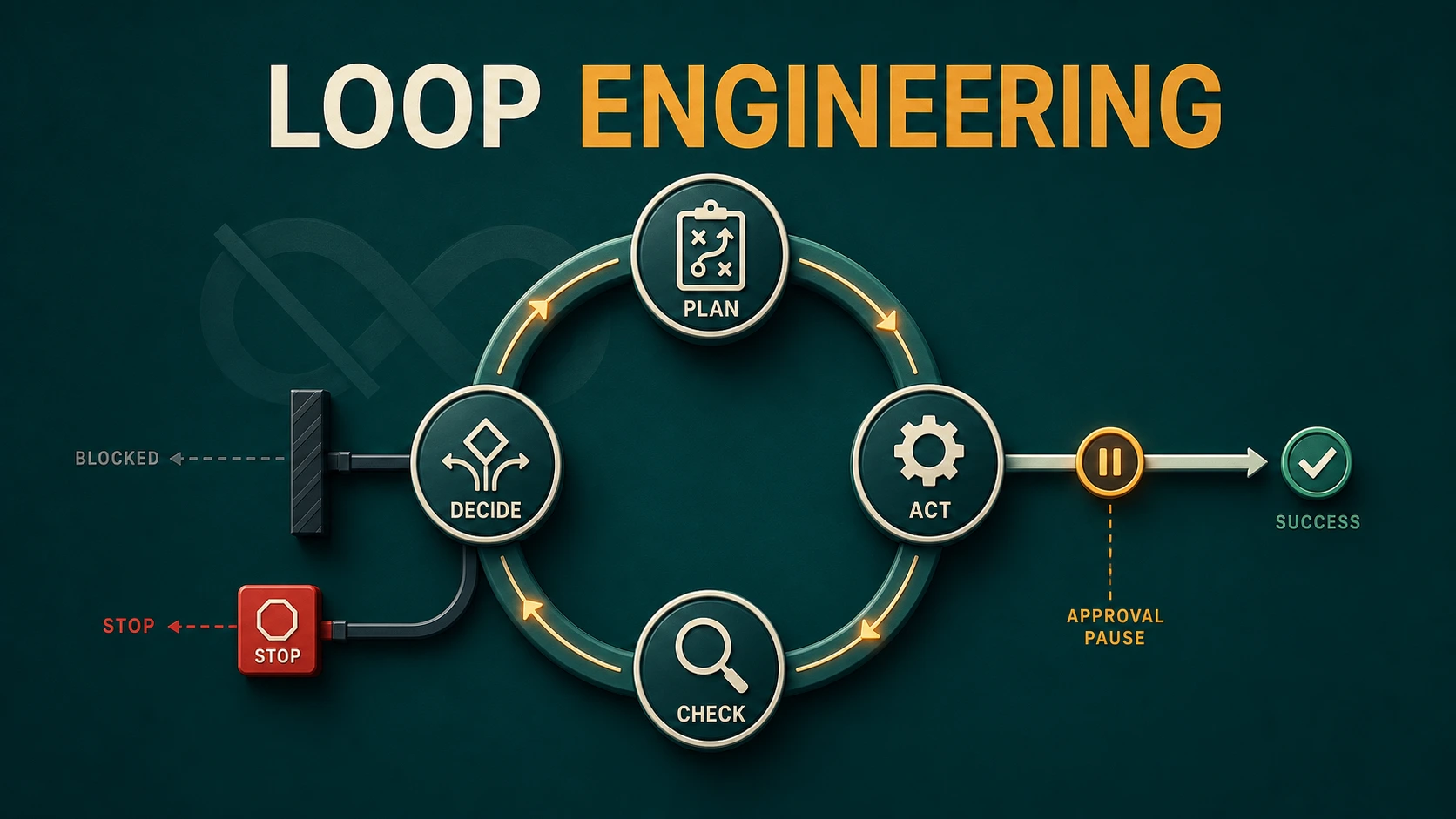
Loop Engineering: Mendesain AI Agent Tanpa Infinite Loop
Desain loop AI agent yang punya indikator progress, retry policy, idempotency, budget, recovery, approval, dan kondisi berhenti yang dapat dibuktikan.

OpenClaw & AI Operasional
Harness Engineering untuk AI Agent: Kenapa Prompt Bagus Belum Cukup
Harness menghubungkan AI agent dengan environment, tools, guardrails, observability, recovery, dan bukti hasil. Inilah komponen yang tidak bisa digantikan prompt.

OpenClaw & AI Operasional
Hermes Agent 0.19.1: Patch Besar untuk Telegram, SQLite WAL, dan Media
Hermes Agent 0.19.1 membawa patch besar untuk silent outage Telegram, SQLite WAL, delivery media, installer, dan updater. Ini risiko serta checklist upgrade aman.
Sebelum checkout
Yang termasuk & tidak termasuk
Transparan sejak awal supaya tidak ada kejutan biaya di tengah jalan.
Termasuk dalam paket
- Scope call dan sizing kebutuhan AI lokal sebelum eksekusi
- Hardware sesuai paket atau unit setara berdasarkan ketersediaan
- Instalasi OS, driver GPU, runtime local AI, dan model awal
- Setup OpenClaw untuk AI agent management dan workflow dasar
- Akses internal via browser, API, atau LAN sesuai kebutuhan
- Benchmark awal, dokumentasi, training, dan handover
Belum termasuk
- Biaya renovasi ruangan, rack, listrik khusus, AC, UPS besar, atau network enterprise di luar scope paket
- Lisensi software pihak ketiga yang tidak disebutkan dalam paket
- Migrasi seluruh dokumen perusahaan ke knowledge base besar tanpa add-on RAG
- Maintenance bulanan, SLA, dan monitoring jangka panjang kecuali dibeli terpisah
- Jaminan performa untuk semua model dan semua context length tanpa benchmark final
FAQ
Pertanyaan seputar Local AI Server untuk Perusahaan
Apakah semua paket bisa checkout langsung? +
Bisa. Semua paket di halaman ini diarahkan ke checkout dan membuat invoice transfer manual. Untuk paket enterprise, checkout dianggap sebagai paket awal sesuai harga minimum dan scope final tetap dikunci setelah konsultasi.
Apakah checkout memakai payment gateway? +
Tidak untuk layanan ini. Checkout membuat invoice dan instruksi transfer manual ke rekening perusahaan. Tim Rama Digital akan melakukan konfirmasi manual setelah pembayaran.
Apakah harga sudah termasuk hardware? +
Ya, paket utama sudah termasuk hardware dan setup sesuai scope paket. Harga bisa berubah jika ada perubahan stok, harga GPU, spesifikasi final, atau kebutuhan enterprise tambahan.
Berapa lama pengerjaan normalnya? +
Workstation biasanya 2-3 minggu, DGX Spark 2-4 minggu, Office Server 3-5 minggu, dan Enterprise 4-8 minggu. Timeline final mengikuti ketersediaan hardware, akses lokasi, network, dan kompleksitas knowledge base.
Model berapa parameter yang bisa dijalankan? +
Workstation cocok untuk 4B-12B quantized, Office Server untuk 4B-32B quantized, dan Enterprise untuk 32B-70B quantized tergantung GPU dan konfigurasi. DGX Spark kuat untuk prototyping model besar berbasis quantization karena memory 128GB.
Apakah data benar-benar tidak keluar dari kantor? +
Local model dan knowledge base bisa berjalan lokal. Namun integrasi tertentu, update, remote support, atau tools eksternal bisa memakai internet jika diaktifkan. Scope keamanan dan batas koneksi akan dijelaskan saat setup.
Apakah bisa tanpa hardware dari Rama Digital? +
Bisa, tetapi hardware client perlu diaudit dulu. Jika sudah cukup, Rama Digital bisa mengerjakan instalasi, konfigurasi, OpenClaw, benchmark, dokumentasi, dan training sebagai scope terpisah.
Siap mulai?
Mulai Local AI Server untuk Perusahaan hari ini
Checkout langsung, atau jadwalkan konsultasi gratis 30 menit untuk membahas kebutuhan Anda dulu.