Gemma 4: cara pakai, spek laptop, dan realita tokens per second
Gemma 4 menarik bukan karena namanya baru. Yang menarik adalah ini: Google mulai mendorong open model yang cukup serius untuk dipakai lokal, tapi masih realistis untuk laptop dan desktop biasa jika kita memilih varian yang tepat.
Masalahnya, banyak orang langsung lompat ke pertanyaan yang salah.
"Bisa jalan di laptop saya?"
Bisa. Tapi itu belum cukup.
Pertanyaan yang lebih penting: jalan seberapa cepat, model mana yang masuk akal, dan kapan ukuran model justru jadi beban?
Kalau targetnya cuma berhasil install, Gemma 4 kecil bisa jalan di banyak mesin. Kalau targetnya dipakai kerja harian, agent kecil, summarize dokumen, bantu coding ringan, atau eksperimen local AI tanpa API cloud, kita perlu melihat RAM, VRAM, ukuran quant, context window, dan tokens per second.
Artikel ini merangkum dari dokumen resmi Google, tag Ollama, benchmark komunitas, dan benchmark internal Rama Digital di laptop Ryzen 9 8945H + RTX 4060 Laptop 8 GB.
Ringkasan cepat
Kalau mau langsung ambil keputusan:
- Laptop RAM 8 GB: mulai dari
gemma4:e2b-it-qat. - Laptop RAM 16 GB: target paling aman
gemma4:e4b-it-qat. - Laptop RAM 32 GB atau Mac Apple Silicon 24-32 GB unified memory: coba
gemma4:12b-it-qat, tapi anggap ini model kualitas, bukan model paling cepat. - Desktop RTX 3090/4090 24 GB: mulai menarik untuk
gemma4:26b-a4b-it-qatatau quant 4-bit/8-bit. - Jangan mulai dari
gemma4:31bkalau mesin masih laptop biasa. - Di benchmark internal Rama Digital,
gemma4:e4b-it-qatberjalan sekitar 69 tok/s di RTX 4060 Laptop 8 GB, sementaragemma4:12b-it-qatsekitar 19.5 tok/s.
Untuk rasa chat, patokan kasar:
- di bawah 10 tokens/sec: terasa lambat,
- 10-15 tokens/sec: masih usable,
- 15-30 tokens/sec: cukup nyaman,
- 30-50 tokens/sec: enak,
- di atas 50 tokens/sec: terasa cepat.
Jangan terlalu terpaku pada satu angka benchmark. Tokens per second bisa berubah banyak karena runtime, quantization, context length, GPU offload, prompt size, dan apakah model benar-benar masuk GPU atau tumpah ke RAM/CPU.
Apa itu Gemma 4?
Gemma adalah keluarga open model dari Google DeepMind. Di model card resminya, Gemma 4 disebut sebagai model multimodal: bisa menerima input text dan image, dengan audio didukung pada varian E2B, E4B, dan 12B. Output utamanya tetap text.
Varian resminya:
E2B: kecil, target mobile/edge dan laptop ringan.E4B: masih kecil, tapi lebih kuat untuk laptop.12B: target laptop kuat, desktop, atau small server.26B A4B: Mixture-of-Experts, total 26B tetapi active sekitar 4B saat inference.31B: dense model besar untuk workstation/server.
Context window juga besar:
- E2B dan E4B: 128K token.
- 12B, 26B A4B, dan 31B: 256K token.
Ini angka yang menggiurkan. Tapi perlu realistis: support context 256K tidak berarti laptop nyaman dipakai 256K setiap hari. Context panjang makan memory dan memperlambat prefill. Untuk kerja harian, sering kali context 4K-32K sudah jauh lebih sehat.
Cara paling gampang pakai Gemma 4 di laptop
Jalur paling praktis untuk mulai adalah Ollama. Download dulu dari halaman resmi Ollama.
Lalu cek dari terminal:
ollama --version
Pull model default:
ollama pull gemma4
Jalankan:
ollama run gemma4 "Jelaskan AI agent untuk bisnis dengan bahasa sederhana."
Kalau mau pilih model yang lebih spesifik, saya sarankan mulai dari QAT:
ollama pull gemma4:e2b-it-qat
ollama run gemma4:e2b-it-qat "Buat ringkasan 5 poin tentang local AI."
Untuk laptop 16 GB:
ollama pull gemma4:e4b-it-qat
ollama run gemma4:e4b-it-qat "Bantu susun outline artikel tentang AI workflow."
Untuk laptop kuat atau Mac RAM besar:
ollama pull gemma4:12b-it-qat
ollama run gemma4:12b-it-qat "Review prompt ini dan buat versi yang lebih tajam."
Ollama juga otomatis menyediakan API lokal di port 11434.
curl http://localhost:11434/api/generate -d '{
"model": "gemma4:e4b-it-qat",
"prompt": "Buat outline SOP follow-up lead untuk agency digital marketing."
}'
Untuk image input, dokumentasi Google memberi contoh menjalankan Gemma 4 lewat Ollama dengan path gambar:
ollama run gemma4 "caption this image /path/to/image.png"
Catatan penting: jalur Ollama yang paling praktis saat ini terutama text/image. Kalau ingin eksplor audio atau multimodal lebih dalam, cek dulu runtime yang dipakai karena tidak semua capability model card otomatis nyaman tersedia di semua runtime lokal.
Ukuran model di Ollama
Tag Ollama membantu kita melihat ukuran file yang perlu disiapkan. Ini bukan total RAM final, karena masih ada overhead runtime dan KV cache, tapi cukup untuk perkiraan awal.
| Model | Ukuran Ollama | Context | Cocok untuk |
|---|---|---|---|
gemma4:e2b-it-qat |
4.3 GB | 128K | laptop ringan, eksperimen cepat |
gemma4:e4b-it-qat |
6.1 GB | 128K | laptop 16 GB, daily local chat |
gemma4:12b-it-qat |
7.2 GB | 256K | laptop kuat, Mac RAM besar |
gemma4:26b-a4b-it-qat |
16 GB | 256K | desktop GPU besar |
gemma4:31b-it-qat |
19 GB | 256K | workstation/server |
Yang perlu dilihat bukan cuma ukuran file. Saat inference, model juga butuh memory untuk runtime, context/KV cache, prompt, dan proses lain di OS. Karena itu model 7.2 GB tidak otomatis nyaman di laptop 8 GB. Bisa jalan, tapi kepala laptop bisa panas, swap bisa aktif, dan respons bisa terasa berat.
Benchmark komunitas: berapa tokens per second?
Sekarang bagian yang paling sering ditanyakan: seberapa cepat?
E2B di laptop GPU 4 GB: 17 tok/s CPU, 39 tok/s hybrid GPU
Ada benchmark komunitas yang menjalankan gemma4:e2b di laptop Ryzen 5 4600H dengan NVIDIA GTX 1650 Ti Mobile 4 GB VRAM, via Ollama.
Hasilnya:
- CPU only: sekitar 17 tokens/sec.
- Hybrid GPU: sekitar 39 tokens/sec.
- Per-call latency turun dari sekitar 5.5 detik menjadi sekitar 2 detik.
- GPU offload menempatkan 35 dari 36 layer ke GPU.
Ini menarik karena 4 GB VRAM bukan hardware mewah. Tapi hasilnya sudah cukup untuk fitur lokal yang pendek: generate distraktor, hint, short explanation, summarize kecil, atau bantuan teks singkat.
Yang juga penting: benchmark itu menjelaskan kenapa speed tidak naik 10x. Ada satu layer penting yang tetap di CPU karena Gemma 4 punya vocabulary besar. Jadi setiap token masih kena bottleneck CPU. Ini pelajaran bagus: hybrid GPU tidak selalu berarti semua pekerjaan selesai di GPU.
E2B dan E4B di Mac 16 GB: 55 tok/s vs 30 tok/s
Benchmark komunitas lain mencoba Gemma 4 untuk workflow OpenClaw di base Mac 16 GB.
Hasil prompt sederhana:
gemma4:e2b: eval rate sekitar 55.35 tokens/sec.gemma4:e4b: eval rate sekitar 30.13 tokens/sec.
E2B jelas lebih cepat. Tapi E4B dipilih karena responsnya terasa lebih baik dan tetap cukup nyaman. Ini sesuai dengan pola yang sering terjadi di local model: model kecil menang speed, model sedikit lebih besar menang rasa jawaban.
Untuk kerja harian, 30 tokens/sec itu sudah enak. Apalagi untuk chat, ringkasan, dan agent ringan yang outputnya tidak terlalu panjang.
12B QAT: sweet spot untuk laptop kuat
Untuk gemma4:12b-it-qat, data komunitas yang rapi belum sebanyak E2B/E4B, tetapi ukuran Ollama-nya menarik: sekitar 7.2 GB untuk QAT, dengan context 256K.
Saya tidak akan mengarang angka pasti. Estimasi realistisnya:
- di laptop CPU-only: bisa jalan, tapi jangan berharap cepat;
- di Mac Apple Silicon dengan unified memory besar: kemungkinan masuk zona usable;
- di laptop/desktop dengan GPU yang cukup: bisa jadi sweet spot antara kualitas dan kecepatan;
- untuk agent atau coding ringan, 12B lebih layak dicoba daripada memaksakan 31B.
Kalau laptop Anda RAM 32 GB, saya akan mulai dari gemma4:12b-it-qat, bukan langsung 26B atau 31B.
26B A4B: besar di nama, tapi cepat karena MoE
Gemma 4 26B A4B menarik karena ini Mixture-of-Experts. Total parameternya 25.2B, tetapi active parameters sekitar 3.8B saat inference.
Efeknya: dia tidak terasa seperti dense 26B biasa. Model card Google sendiri menjelaskan bahwa 26B A4B bisa berjalan jauh lebih cepat daripada ukuran totalnya karena hanya subset expert yang aktif.
Di issue Ollama untuk gemma4:26b-a4b-it-q8_0, ada contoh run 100% GPU dengan angka:
- eval rate sekitar 43 tokens/sec saat flash attention aktif di kasus tertentu,
- sekitar 66 tokens/sec saat setting berbeda,
- prompt eval bisa berubah drastis tergantung konfigurasi.
Ini bukan benchmark final, tapi cukup memberi gambaran: di GPU besar, 26B A4B bisa sangat menarik. Untuk desktop RTX 3090/4090 24 GB, varian ini lebih masuk akal dicoba dibanding 31B dense jika targetnya speed + kualitas.
31B: kuat, tapi mulai masuk wilayah workstation
Untuk gemma4:31b, komunitas RTX 3090 melaporkan angka sekitar 20-26 tokens/sec pada quant dan context tertentu. Ada juga laporan sekitar 27 tokens/sec di 32 GB VRAM.
Itu masih usable. Tapi ini bukan kelas "laptop biasa".
31B dense lebih berat. Kalau context dinaikkan terlalu tinggi atau model tidak muat penuh di GPU, speed bisa jatuh ke 2-3 tokens/sec. Di titik itu, model memang jalan, tapi pengalaman pakainya tidak enak.
Kesimpulan saya: 31B jangan dijadikan default pertama. Pakai kalau mesin memang siap dan use case memang butuh.
Benchmark internal Rama Digital: Ryzen 9 + RTX 4060 Laptop
Setelah artikel ini pertama kali dipublish, kami menjalankan benchmark sendiri di laptop operasional Rama Digital.
Speknya:
- OS: Fedora Linux 44
- CPU: AMD Ryzen 9 8945H
- GPU: NVIDIA GeForce RTX 4060 Laptop GPU 8 GB
- RAM: 30 GiB
- Ollama: 0.30.8
- Model:
gemma4:e4b-it-qatdangemma4:12b-it-qat - Prompt: fixed coding prompt Nuxt 4
- Requested output: 512 token
- Measured runs: 3 kali per model
- Mode yang diuji:
balanceddanaccelerator-performance
Hasilnya cukup jelas: E4B jauh lebih enak untuk daily local inference. 12B masih usable, tapi lebih cocok dipakai saat kualitas jawaban lebih penting daripada respons cepat.
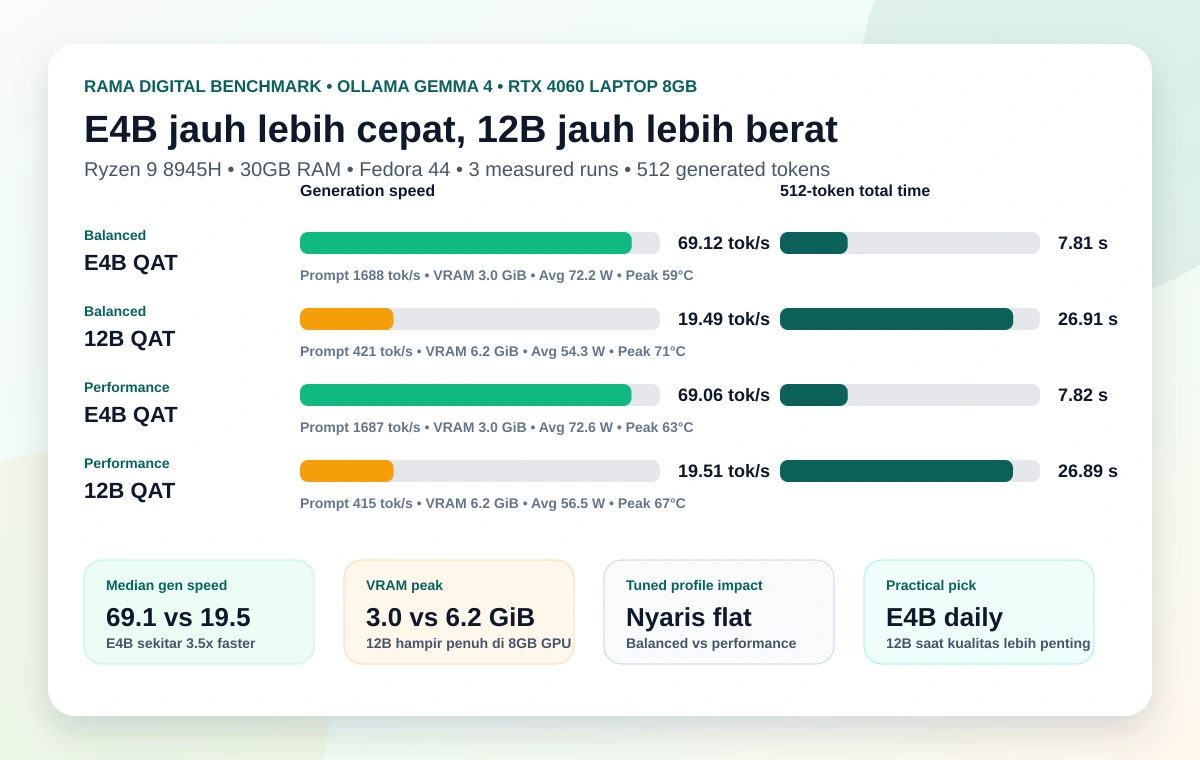
Hasil utama
| Model | Profile | Median gen tok/s | Median total 512 token | Median prompt tok/s | GPU peak | GPU avg W |
|---|---|---|---|---|---|---|
gemma4:e4b-it-qat |
balanced | 69.12 | 7.81 s | 1688.27 | 3048 MiB | 72.15 W |
gemma4:12b-it-qat |
balanced | 19.49 | 26.91 s | 421.16 | 6366 MiB | 54.32 W |
gemma4:e4b-it-qat |
accelerator-performance | 69.06 | 7.82 s | 1687.47 | 3048 MiB | 72.56 W |
gemma4:12b-it-qat |
accelerator-performance | 19.51 | 26.89 s | 415.26 | 6366 MiB | 56.53 W |
Ada beberapa insight yang menurut saya penting.
Pertama, gemma4:e4b-it-qat stabil di sekitar 69 tokens/sec. Untuk local chat, drafting, summarize, dan agent ringan, ini sudah terasa cepat. 512 token selesai sekitar 7.8 detik.
Kedua, gemma4:12b-it-qat stabil di sekitar 19.5 tokens/sec. Ini masih usable, tapi ritmenya beda. Output 512 token butuh sekitar 26.9 detik. Kalau dipakai untuk long answer atau agent yang banyak step, delay-nya akan terasa.
Ketiga, penggunaan VRAM beda jauh. E4B hanya memakai sekitar 3.0 GiB peak, sementara 12B memakai sekitar 6.2 GiB. Di RTX 4060 Laptop 8 GB, 12B sudah dekat ke batas nyaman. Masih jalan, tapi ruang untuk context panjang, multi-process, atau aplikasi GPU lain makin sempit.
Keempat, pindah dari profile balanced ke accelerator-performance nyaris tidak mengubah generation speed. E4B tetap sekitar 69 tok/s, 12B tetap sekitar 19.5 tok/s. Artinya untuk workload ini bottleneck-nya bukan sekadar governor CPU. GPU dan karakter model lebih menentukan.
Jadi rekomendasi saya berubah sedikit:
- Untuk daily local AI di laptop RTX 4060 8 GB, pilih
gemma4:e4b-it-qat. - Untuk jawaban yang butuh model lebih kuat dan user siap menunggu, pakai
gemma4:12b-it-qat. - Jangan jadikan 12B sebagai default untuk semua task kalau workflow-nya banyak output panjang.
- Kalau targetnya agent yang cepat merespons, E4B lebih sehat.
Benchmark ini juga memperkuat satu poin: model "lebih besar" tidak otomatis lebih baik untuk operasional. Kalau 80% pekerjaan hanya butuh respon cepat dan cukup akurat, model yang lebih kecil bisa menghasilkan throughput kerja yang lebih tinggi.
Spek laptop minimum yang realistis
Kalau kita gabungkan ukuran model dan benchmark komunitas, ini rekomendasi praktisnya.
Minimum: RAM 8 GB
Masih bisa coba:
gemma4:e2b-it-qat- context kecil dulu, misalnya 4K-8K
- jangan buka banyak aplikasi berat bersamaan
Target speed realistis: 10-30 tokens/sec tergantung CPU/GPU. Kalau CPU-only dan laptop lama, bisa lebih rendah.
Ini cocok untuk eksperimen, bukan untuk workflow berat.
Nyaman pertama: RAM 16 GB
Model yang masuk akal:
gemma4:e4b-it-qatgemma4:e2b-it-qatkalau butuh speedgemma4:12b-it-qatkalau mau test, tapi jangan pakai context besar dulu
Target speed realistis: 20-50 tokens/sec untuk E2B/E4B di mesin yang mendukung akselerasi dengan baik. Untuk 12B, anggap lebih pelan.
Ini spek yang mulai enak untuk local chat, summarize, prompt helper, dan agent ringan.
Sweet spot: RAM 32 GB atau Mac unified memory besar
Model yang layak dicoba:
gemma4:12b-it-qatgemma4:e4b-it-qatuntuk speedgemma4:26b-a4b-it-qathanya kalau memory/GPU cukup
Di kelas ini, Gemma 4 mulai terasa bukan sekadar demo. Bisa dipakai untuk kerja harian yang lebih serius, termasuk local assistant, drafting, analisa dokumen, dan integrasi ke tool kecil.
Tapi setelah melihat benchmark RTX 4060 Laptop, saya akan tetap memisahkan default harian dan model kualitas. E4B untuk harian, 12B untuk task yang memang layak menunggu.
Desktop/workstation: GPU 24 GB ke atas
Model yang menarik:
gemma4:26b-a4b-it-qatgemma4:26b-a4b-it-q4_K_Mgemma4:31b-it-qatatau Q4, jika memang butuh dense model besar
Kalau pakai RTX 3090/4090 24 GB, perhatikan context dan KV cache. Model bisa muat, tapi context panjang bisa membuat memory tumpah ke CPU. Begitu tumpah, TPS bisa turun parah.
Cara benchmark di laptop sendiri
Cara paling gampang:
ollama run gemma4:e4b-it-qat --verbose
Kirim prompt yang agak panjang, lalu lihat output di akhir.
Yang perlu dicatat:
prompt eval rate: xx tokens/s
eval rate: xx tokens/s
prompt eval rate menunjukkan kecepatan membaca prompt. eval rate menunjukkan kecepatan menghasilkan output. Untuk rasa chat, eval rate biasanya lebih terasa.
Kalau ingin benchmark lebih rapi via API:
curl -s http://localhost:11434/api/generate -d '{
"model": "gemma4:e4b-it-qat",
"prompt": "Buat analisa 5 poin tentang kenapa local AI berguna untuk bisnis kecil.",
"stream": false
}' | jq '{
eval_count,
eval_duration,
eval_rate: (.eval_count / (.eval_duration / 1000000000))
}'
Jalankan beberapa kali. Buang run pertama karena biasanya masih ada load/warm-up. Ambil rata-rata dari run kedua sampai kelima.
Kalau Anda memakai GPU NVIDIA, cek juga:
nvidia-smi
Dan cek log Ollama untuk melihat layer offload:
journalctl -u ollama -n 200 --no-pager | grep -E "offload|layer|gpu"
Di Docker:
docker logs ollama 2>&1 | grep -E "offload|layer|gpu"
Jangan hanya percaya tampilan ollama ps. Beberapa benchmark komunitas menunjukkan bahwa persentase CPU/GPU di sana bisa lebih menggambarkan pembagian memory, bukan selalu jumlah layer yang benar-benar pindah ke GPU.
Model mana yang saya pilih?
Kalau saya harus memilih untuk kebutuhan operasional:
- Laptop biasa:
gemma4:e2b-it-qat. - Laptop 16 GB:
gemma4:e4b-it-qat. - Laptop RTX 4060 8 GB / RAM 32 GB:
gemma4:e4b-it-qatuntuk harian,gemma4:12b-it-qatuntuk task yang butuh kualitas lebih baik. - Desktop GPU 24 GB:
gemma4:26b-a4b-it-qatdulu, baru bandingkan dengan 31B.
Untuk bisnis, saya tidak akan terobsesi menjalankan model terbesar. Yang lebih penting adalah model cukup cepat, cukup pintar, dan bisa masuk ke workflow tanpa membuat operator menunggu terlalu lama.
Local AI yang terlalu lambat akhirnya jarang dipakai. Model yang sedikit lebih kecil tetapi responsif sering lebih berharga daripada model besar yang secara teori lebih pintar tapi membuat setiap task terasa berat.
Kapan Gemma 4 cocok dipakai?
Gemma 4 cocok untuk:
- local chat yang tidak mengirim data ke API luar,
- summarize dokumen internal,
- bantu drafting konten,
- prompt helper,
- light coding,
- klasifikasi teks sederhana,
- agent kecil dengan tools lokal,
- eksperimen multimodal image understanding,
- workflow internal yang butuh privacy.
Gemma 4 kurang cocok kalau Anda butuh:
- kualitas reasoning frontier model untuk semua task,
- coding berat yang harus selalu akurat,
- agent production yang menjalankan aksi penting tanpa guardrail,
- long context 256K secara rutin di laptop biasa,
- latency sangat rendah untuk banyak user sekaligus.
Jadi posisinya jelas: Gemma 4 bagus untuk local-first workflow dan eksperimen serius. Tapi untuk pekerjaan high-stakes atau production besar, tetap perlu arsitektur yang benar: logging, fallback, rate limit, evaluasi output, dan kadang tetap butuh model cloud yang lebih kuat.
Hubungannya dengan AI agent dan workflow bisnis
Gemma 4 bisa menjadi model lokal untuk agent kecil. Tapi model lokal saja belum otomatis membuat bisnis lebih rapi.
Yang menentukan hasil tetap workflow-nya: instruksi kerja, memory, tools, data yang boleh diakses, output format, dan batas kapan agent boleh bertindak.
Kalau Anda sedang belajar membangun agent workflow yang lebih operasional, baca juga artikel kami tentang Jago Hermes Agent. Kelas itu membahas Hermes Agent dari setup sampai workflow bisnis seperti marketing, riset, follow-up, knowledge base, dan operasional.
Untuk konteks multi-agent dan routing bot, kami juga sudah menulis panduan cara membuat multi-agent Hermes dan bot-to-bot Telegram yang aman.
Intinya: model adalah mesin. Workflow adalah sistem. Dua-duanya perlu.
Kesimpulan
Gemma 4 layak dicoba, terutama kalau Anda ingin local AI yang tidak selalu bergantung pada API cloud.
Tapi jangan mulai dari ego model besar. Mulai dari kebutuhan:
- butuh cepat dan ringan: E2B,
- butuh lebih enak untuk kerja harian: E4B,
- butuh kualitas lebih baik di laptop kuat: 12B QAT,
- punya desktop GPU besar: 26B A4B,
- punya workstation dan butuh dense model besar: 31B.
Untuk mayoritas pengguna laptop, gemma4:e4b-it-qat adalah titik mulai paling sehat. Kalau RAM 32 GB atau Mac unified memory besar, gemma4:12b-it-qat menjadi pilihan yang lebih menarik, tapi jangan berharap kecepatannya mendekati E4B.
Benchmark komunitas memberi pesan yang sama: local model bukan soal "bisa jalan atau tidak". Yang penting adalah apakah kecepatannya masuk ke ritme kerja.
Kalau jawabannya ya, Gemma 4 bisa jadi salah satu model lokal paling menarik untuk dicoba sekarang.
Sumber
- Gemma 4 model card
- Get started with Gemma
- Run Gemma with Ollama
- Ollama Gemma 4 tags
- Benchmark Gemma 4 E2B di laptop GPU 4 GB
- Benchmark Gemma 4 E2B/E4B di Mac 16 GB
- Issue Ollama Gemma 4 26B A4B Q8 speed
- Diskusi LocalLLaMA RTX 3090 untuk Gemma 4
- Benchmark internal Rama Digital, 17 Juni 2026: Ryzen 9 8945H, RTX 4060 Laptop 8 GB, Fedora 44, Ollama 0.30.8
Founder Rama Digital. Menulis tentang digital marketing, web development, AI, dan sistem operasional untuk bisnis Indonesia.
Tentang Rama Digital